基于bilibili哈基米音乐视频的用户画像分析与分类研究
摘要
随着短视频与弹幕文化的兴起,Bilibili 评论区已成为年轻人情感表达与兴趣互动的重要场域。结合孙晓彤等人对弹幕评论影响的实证分析与4chan泛帖的数据采集方法,本文聚焦哈基米音乐热门视频评论,收集66,324条互动记录,构建用户情感与行为数据集。通过中文NLP与聚类算法,挖掘用户情感倾向、兴趣主题分布及活跃度分级,为个性化推荐、舆情监测和内容优化提供数据支撑。研究不仅丰富了弹幕用户画像理论,也为短视频平台社区治理与精准营销提供实践参考。
关键词:短视频;弹幕评论;用户画像;情感分析;哈基米音乐
1 引言
1.1 研究背景以及意义
随着短视频与弹幕文化的迅猛发展,Bilibili 已成为中国年轻人文化交流的重要平台。作为一个集视频分享、实时互动与社区建设于一体的综合性网站,Bilibili 不仅吸引了大量内容创作者和观众,也积累了海量的用户评论数据。孙晓彤,金福杰,张静.在《Influence of Danmaku Comments on User Engagement in Short-Form Videos》基于自然实验,考察了弹幕评论(DMC)对短视频平台用户参与度的影响。通过利用中国某主流短视频平台引入弹幕评论的契机,采用双重差分法,发现弹幕评论显著提高了点赞与分享数量,同时降低了常规评论数量。此外,弹幕评论对不同创作者的影响存在异质性,知名度较低以及制作时长较长的视频创作者受益更多。研究结果丰富了用户参与度相关文献,并为短视频平台的弹幕功能设计提供了实务指导。^[Sun, X., Jin, F., & Zhang, J. (2024). Influence of Danmaku Comments on User Engagement in Short-Form Videos. ICIS 2024 Proceedings, 32.]这些评论覆盖了从二次元、游戏、音乐到科技、知识等多个兴趣领域,形成了高度活跃且具有强烈社区归属感的用户生态。
在评论区,用户以弹幕、文字评论等多种形式频繁互动,这种互动行为不仅仅是个体情感与观点的直接表达,更反映了用户对内容的接受度、价值取向以及社会议题的态度。同时,评论中还蕴含着用户深层次的兴趣偏好、消费倾向与潜在的行为模式。通过对这些评论数据的深入分析,可以挖掘出群体性的情感趋势、流行话题演变路径,以及用户之间潜在的社交网络关系。
因此,Bilibili 的评论区不仅是一个舆论表达空间,更是观察和理解当代中国年轻人文化心理与社会互动的重要窗口。如何科学、高效地利用这一丰富的数据资源,对于内容推荐优化、用户画像构建以及社区治理等方面都具有重要的理论价值与应用前景。
Jokubauskaitė E, Peeters S.在《Generally Curious: Thematically Distinct Datasets of General Threads on 4chan/pol/》对自2010年代中后期以来,4chan 的 /pol/(政治不正确)版块成为极端政治意识形态的交流与扩散空间。以往研究多将该社区视为一个整体进行分析,本文则针对其中的“泛帖”(generals)——具有特定话题、以特定标签或短语标识的重复性主题帖——进行了划分与数据集构建。作者通过系统收集与查询协议,整理出包含58,841个首帖与13,697,738条回复的329个主题化泛帖子集。^[Jokubauskaitė, E., & Peeters, S. (2020). Generally Curious: Thematically Distinct Datasets of General Threads on 4chan/pol/. Proceedings of the International AAAI Conference on Web and Social Media (ICWSM), 14(1). https://doi.org/10.1609/icwsm.v14i1.7351 ]本文详细介绍了数据采集方法、数据结构设计以及未来的研究应用方向。参考此文献的研究方法,本文对Bilibili相关评论进行了详细研究。
1.2 主要研究内容
哈基米音乐作为新时代年轻人追捧的流行元素,凭借其节奏感强、氛围轻松、极具辨识度的音乐风格,迅速在各大社交平台走红,成为短视频、弹幕文化与潮流生活方式的重要组成部分。哈基米音乐不仅满足了年轻人对个性化音乐体验的需求,更成为情绪表达、社交互动与文化认同的载体。
在这一背景下,本文基于哈基米音乐排行榜的热门视频,选取该视频评论区作为研究对象,对用户互动数据进行系统分析。针对哈基米音乐视频这一新兴流行元素,本文共收集了 66,324 条评论数据,涵盖了45,304 名用户的互动记录。通过深入挖掘这些用户评论,能够全面揭示用户群体的情感倾向、兴趣主题分布及活跃度等级,为平台的个性化推荐系统、舆情监测机制以及优质内容优化提供科学的数据支撑。
本文共五章:第一章介绍研究背景、现状及意义,明确研究目标与内容;第二章阐述中文自然语言处理、文本挖掘、情感分析、聚类算法与用户画像的理论基础及关键技术;第三章设计搭建哈基米音乐用户画像分析系统,详细说明系统架构、数据采集与分析方法;第四章基于系统对评论数据展开实验,涵盖数据预处理、情感建模、兴趣主题划分及用户活跃度分级,最终形成用户画像并进行可视化;第五章总结全文,探讨成果应用及未来改进方向。
2 相关技术以及理论
2.1 文本预处理与情感分析
在文本挖掘流程中,中文分词与停用词处理是基础步骤。本文采用 jieba 库进行细粒度分词,并结合自定义停用词表剔除无意义词项,确保后续特征提取的有效性。Jalilifard A, Caridá V F等人在《Semantic Sensitive TF-IDF to Determine Word Relevance in Documents》针对非正式文本的关键词提取问题,提出一种基于TF-IDF的语义敏感方法(STF-IDF),利用大规模健康社交媒体语料训练词嵌入,通过迭代优化TF-IDF评分,显著降低平均误差率,提升关键词提取准确性。^[Jalilifard, A., Caridá, V. F., Mansano, A. F., Cristo, R. S., & da Fonseca, F. P. C. (2021). Semantic sensitive TF-IDF to determine word relevance in documents. In Advances in Computing and Network Communications: Proceedings of CoCoNet 2020, Volume 2 (pp. 327-337). Springer Singapore.]所以,基于清洗后的评论文本,使用 TfidfVectorizer 提取关键词权重,以量化用户表达的主题信息,为聚类分析提供高维特征矩阵。
用户情感倾向是用户画像的重要维度之一。何波, 王磊等人在《Analysis of Online Public Opinion Texts Based on Topic Mining and Sentiment Analysis》综述了基于主题挖掘和情感分析的舆情文本分析方法,探讨其基本概念及特点,分析国内外研究成果。比较不同方法的优缺点,总结当前研究的优势和局限,提出未来的发展方向和趋势。该研究利用 SnowNLP 模块对微博评论文本数据进行情感分析,计算情感得分分布,并使用支持向量机(SVM)进行情感分类。^[He, B., Wang, L.* , Zhao, R., & Yang, Y. (Year unknown). Analysis of Online Public Opinion Texts Based on Topic Mining and Sentiment Analysis. School of Computer Science and Engineering, Chongqing University of Technology, Chongqing, China.]参考该文章研究方法,本文利用 SnowNLP 对每条评论进行情感极性打分,生成用户级别的情感得分分布。通过该方法,可识别出不同用户群体在哈基米音乐视频下的正负面倾向差异,为平台情绪监测与社区引导策略提供参考。
2.1.1 朴素贝叶斯分类器(Naive Bayes Classifier)
朴素贝叶斯分类器(Naive Bayes Classifier)是一种基于贝叶斯定理与特征条件独立假设的概率分类模型。其核心思想是:在已知样本某些特征的条件下,利用概率推断的方式,判断该样本最可能属于哪个类别。由于其计算简单、效果稳定,广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
朴素贝叶斯分类器建立在贝叶斯定理(Bayes Theorem)的基础上,贝叶斯定理描述了后验概率与先验概率、似然概率之间的关系:
$$
P(C|X) = \frac{P(X|C) \cdot P(C)}{P(X)}
$$
其中:
- $P(C∣X)$:在已知特征 X 的情况下,样本属于类别 C 的后验概率。
- $P(C)$:类别 C 的先验概率。
- $P(X∣C)$:在类别 C 条件下特征 X 出现的概率(似然)。
- $P(X)$:特征 X 出现的概率。
朴素贝叶斯分类器理论简单、计算高效,适用于大规模数据,且对小样本集有良好表现,支持多类别分类。然而,该方法强依赖特征条件独立性,实际应用中这一假设常常难以满足,对特征高度相关的数据集分类效果有限,可能影响准确性。
2.1.2 TF-IDF(Term Frequency - Inverse Document Frequency)算法
TF-IDF(词频-逆文档频率,Term Frequency - Inverse Document Frequency)是一种广泛应用于文本挖掘与信息检索的关键词提取与特征加权方法。它通过衡量词语在文档中的重要性,帮助过滤掉常见但无实际区分度的词汇(如“的”、“是”等停用词),重点突出能够代表文本主题的关键内容。
TF-IDF 的核心在于结合词频与逆文档频率,衡量词语的重要性。词频(TF)表示词语在当前文档中的出现频率,突出其对该文档的代表性;逆文档频率(IDF)衡量词语在整个语料库中的稀有程度,出现越少的词越具有区分力,从而降低高频常见词的权重,突出关键词。其公式定义:
词频(TF)
$$
% 词频(TF)公式
TF(t, d) = \frac{f_{t,d}}{\sum_{k} f_{k,d}}
$$逆文档频率(IDF)
$$
% 逆文档频率(IDF)公式
IDF(t) = \log \frac{N}{n_t}
$$
为避免分母为零,实际应用中常采用平滑处理:
$$
% IDF 平滑处理公式
IDF(t) = \log \frac{N}{1 + n_t}
$$TF-IDF 权重
$$
% TF-IDF 权重公式
TF\text{-}IDF(t, d) = TF(t, d) \times IDF(t)
$$
该权重越高,说明词语 t 对文档 d 的区分能力越强。
TF-IDF 方法简单高效,能够有效衡量词语在当前文档中的重要性,广泛应用于文本挖掘与信息检索。然而,该方法无法捕捉词语的上下文和语义关联,对长文档易产生偏差,可能被高频词影响。此外,TF-IDF 仅依赖词频统计,忽略了词序与语法结构,存在一定局限性。
2.2 聚类算法与评价指标
为实现用户群体划分,本文先后采用 K-means 与 DBSCAN 两种无监督聚类算法。K-means 聚类能够快速划分出均衡簇;而 DBSCAN 则针对噪声点具有更强鲁棒性,可捕捉任意形状的簇结构。Rousseeuw, P. J.在《Silhouettes: A graphical aid to the interpretation and validation of cluster analysis》的研究中提出了一种新的图形展示方法——轮廓图(silhouette),用于聚类结果的解释和验证。轮廓图通过比较簇的紧密度和分离度,展示每个对象属于其簇的程度,揭示哪些对象位于簇中心,哪些介于簇间。整体聚类通过所有轮廓图合成一图展现,帮助评估簇的质量及数据结构。平均轮廓宽度可作为聚类有效性的指标,并可用于确定合适的聚类数^[Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53–65. https://doi.org/10.1016/0377-0427(87)90125-7 ]所以,在聚类效果方面,引入轮廓系数(silhouette score)进行定量评估,以综合考虑簇内紧凑度与簇间分离度。
2.2.1 K-means聚类算法
K-means 聚类算法是一种基于距离度量的无监督学习方法,旨在将数据集划分为 KKK 个不同的簇(Cluster),使得同一簇内的样本相似度尽可能高,不同簇之间的样本差异尽可能大。该算法以高效、易实现的优点,广泛应用于用户画像、文本分类、图像分割等场景。
K-means 的核心思想是通过迭代优化目标函数,最小化簇内样本到各自质心的总距离(平方误差和)。目标函数(优化目标)为:
$$
% K-means 聚类目标函数
J = \sum_{j=1}^{K} \sum_{i=1}^{n_j} | x_i^{(j)} - \mu_j |^2
$$
其中:
- K:聚类的簇数;
- $n_j$:第 j 个簇中的样本数;
- $x_i^{(j)}$:第 j 个簇中的第 i 个样本;
- $\mu_j$:第 j 个簇的质心。
K-means 聚类算法主要包括四个步骤:首先随机选择 K 个初始质心;然后将每个样本划分到与其距离最近的质心所属簇中;接着重新计算各簇样本的均值作为新的质心;最后不断重复样本分配与质心更新,直至质心收敛或达到预设迭代次数。
2.2.2 DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够有效发现任意形状的高密度区域,并自动识别噪声点。相比 K-means,DBSCAN 不需要预先指定簇的数量,且对异常值具有较强的鲁棒性,广泛应用于用户行为分析、空间数据挖掘等领域。
DBSCAN 聚类算法根据邻域密度将样本划分为三类:核心点、边界点和噪声点。核心点指邻域内样本数不少于 MinPts 的高密度点,边界点虽邻域内样本不足,但位于核心点邻域内,噪声点则既非核心点也不属于任何核心点邻域,被视为异常点。
该方法无需预设簇数,能识别任意形状的簇,且对噪声与异常值具有较强鲁棒性。然而,它对参数 ε 和 MinPts 较为敏感,在高维数据集上可能因“维度灾难”而表现不佳。
2.3 降维与可视化
为便于分析与展示,将高维特征通过 PCA 主成分分析降至二维空间,并结合散点图、词云等可视化手段直观呈现用户聚类结果与主题分布特征。同时,借助 StandardScaler 对特征进行标准化处理,确保不同量纲特征在降维与聚类中的均衡贡献。
2.3.1 PCA(主成分分析,Principal Component Analysis)
主成分分析(PCA)是一种常用的数据降维方法,主要通过线性变换将原始高维数据映射到较低维度空间,最大限度保留原始数据的主要特征。PCA 能有效减少数据冗余,降低计算复杂度,同时便于数据可视化和后续分析。
PCA 通过计算样本的协方差矩阵,提取数据中方差最大的方向,称为“主成分”。各主成分之间相互正交、不相关。目标是找到一组新的坐标轴,使得投影后的数据在前几个主成分上具有最大的方差,从而达到降维效果。
该算法首先对原始数据进行中心化标准化,确保各特征均值为零;随后计算协方差矩阵以衡量特征间的线性关系。接着求解协方差矩阵的特征值与特征向量,并按特征值大小排序,选择前 k 个主成分。最后,将原始数据投影到所选主成分空间,实现降维。该方法能有效降低数据维度,减少噪声干扰,计算速度快,便于可视化和后续建模。但其仅适用于线性降维,难处理非线性关系,降维后的主成分难以直接解释,且对异常值较为敏感,可能影响效果。
2.3.2 StandardScaler(标准化)
标准化是数据预处理中的常用技术,旨在将不同量纲或尺度的特征转换到统一的标准尺度,消除量纲影响,提升后续算法的稳定性和性能。StandardScaler 是常见的标准化方法之一,其基本思想是将每个特征的值减去均值后再除以标准差,使转换后的特征服从均值为 0、标准差为 1 的标准正态分布。
对于样本数据中第 j 个特征的 i 个值 $x_{ij}$,标准化过程为:
$$
x_{ij}^{‘} = \frac{x_{ij} - \mu_j}{\sigma_j}
$$
其中:
- $\mu_j$ 为第 j 个特征的均值;
- $\sigma_j$ 为第 j 个特征的标准差。
标准化能够消除不同特征的量纲差异,使各特征具备可比性;这对于基于距离的算法(如 K-means、KNN)显著提升聚类与分类效果;同时也加快梯度下降等优化算法的收敛速度,提高其稳定性。
2.4 分类算法与用户标签验证
Probst P, Wright M在《Hyperparameters and Tuning Strategies for Random Forest》综述了随机森林(Random Forest, RF)算法的关键超参数及其对预测性能和变量重要性评估的影响。尽管RF在大多数情况下使用默认参数已能取得良好效果,但合理的参数调优可进一步提升模型性能。作者介绍了主流的调优策略,重点展示了基于模型的优化(MBO)方法,并提供了可自动调参的R语言工具包tuneRanger。通过多个数据集的基准实验,比较了tuneRanger与其他R调优工具及默认参数下的性能与运行时间。^[Probst, P., Wright, M. N., & Boulesteix, A. L. (2019). Hyperparameters and tuning strategies for random forest. Wiley Interdisciplinary Reviews: data mining and knowledge discovery, 9(3), e1301.]参考文献的研究方法,在完成聚类分析后,基于 RandomForestClassifier 与 SVC 模型构建用户标签分类器,通过交叉验证评估分类准确率与稳定性,为聚类标签的有效性提供进一步验证。此环节不仅可辅助平台自动化打标,也为后续实时用户画像更新奠定技术基础。
2.4.1 RandomForestClassifier(随机森林分类器)
随机森林(Random Forest)是一种集成学习方法,主要通过构建多个决策树并结合其结果进行分类或回归。它通过引入随机性,增强模型的泛化能力和鲁棒性,是目前广泛应用且效果稳定的分类算法之一。
随机森林基于决策树模型,采用两种随机策略构建多棵树:一是样本随机抽样(Bagging),即对训练数据进行有放回抽样,生成不同子样本集,每个子样本用于训练一棵决策树;二是在节点划分时随机选择部分特征,避免所有树都选取最优特征,增强多样性。最终通过多数投票(分类)或平均值(回归)整合各树结果,提高整体预测准确度。
随机森林抗过拟合能力强,适合处理高维和大规模数据,具有较高鲁棒性,对噪声与异常值不敏感。同时无需复杂参数调节,使用便捷。此外,它还能评估特征重要性,帮助理解模型决策依据。
2.4.2 SVC(支持向量分类器)
支持向量分类器(Support Vector Classifier,SVC)是支持向量机(SVM)在分类问题中的具体实现,旨在寻找一个最优分割超平面,以最大化不同类别间的间隔(margin),从而实现准确分类。
SVC通过构造最大间隔的超平面,将两类样本分开,从而提升模型的泛化能力。距离超平面最近的样本点称为支持向量,它们决定了超平面的具体位置。借助核函数技巧,SVC能在高维特征空间处理线性不可分的数据,常用核函数包括线性核、多项式核及径向基函数(RBF)。
优点方面,SVC在高维空间表现优异,能有效处理非线性分类问题,具备坚实的理论基础和稳定的泛化能力,且对少量样本的数据分类效果较好。缺点则包括训练时间较长,尤其面对大规模数据时;参数调优较为复杂,需选择合适的核函数及其参数;此外,对噪声和异常值较为敏感。
2.4.3 K折交叉验证(K-Fold Cross Validation)
K折交叉验证是一种常用的模型评估方法,用于衡量机器学习模型的泛化能力。它将数据集平均分成 K 个子集,每次使用其中一个子集作为验证集,剩余 K−1 个子集作为训练集,重复训练与验证 K 次,最终将所有轮次的评估结果取平均。
交叉验证有效避免过拟合,使评估结果更稳定可靠;充分利用数据,尤其适合样本量有限的场景。其流程包括:将数据集随机划分为 K 个大小相近的子集,依次选取其中一个子集作为验证集,其余作为训练集,进行模型训练与验证并记录指标,最终计算 K 次验证的平均指标,作为模型性能的综合评估。
3 系统设计与总体框架
3.1 数据预处理
3.1.1 数据采集模块
通过调用 Bilibili 开放 API,选取哈基米音乐排行榜中的 32 个热门视频,累计抓取 66 324 条评论数据。为确保数据的完整性与代表性,重点采集了视频评论、用户昵称、评论时间、点赞数等关键字段。
基于数据爬虫,本研究共收集了 66,324 条评论数据,涵盖了45,304 名用户的互动记录。通过对这些用户评论进行深入挖掘,能够全面地揭示用户群体的情感倾向、兴趣主题分布及活跃度等级,为平台的个性化推荐系统、舆情监测机制以及优质内容优化提供科学的数据支撑。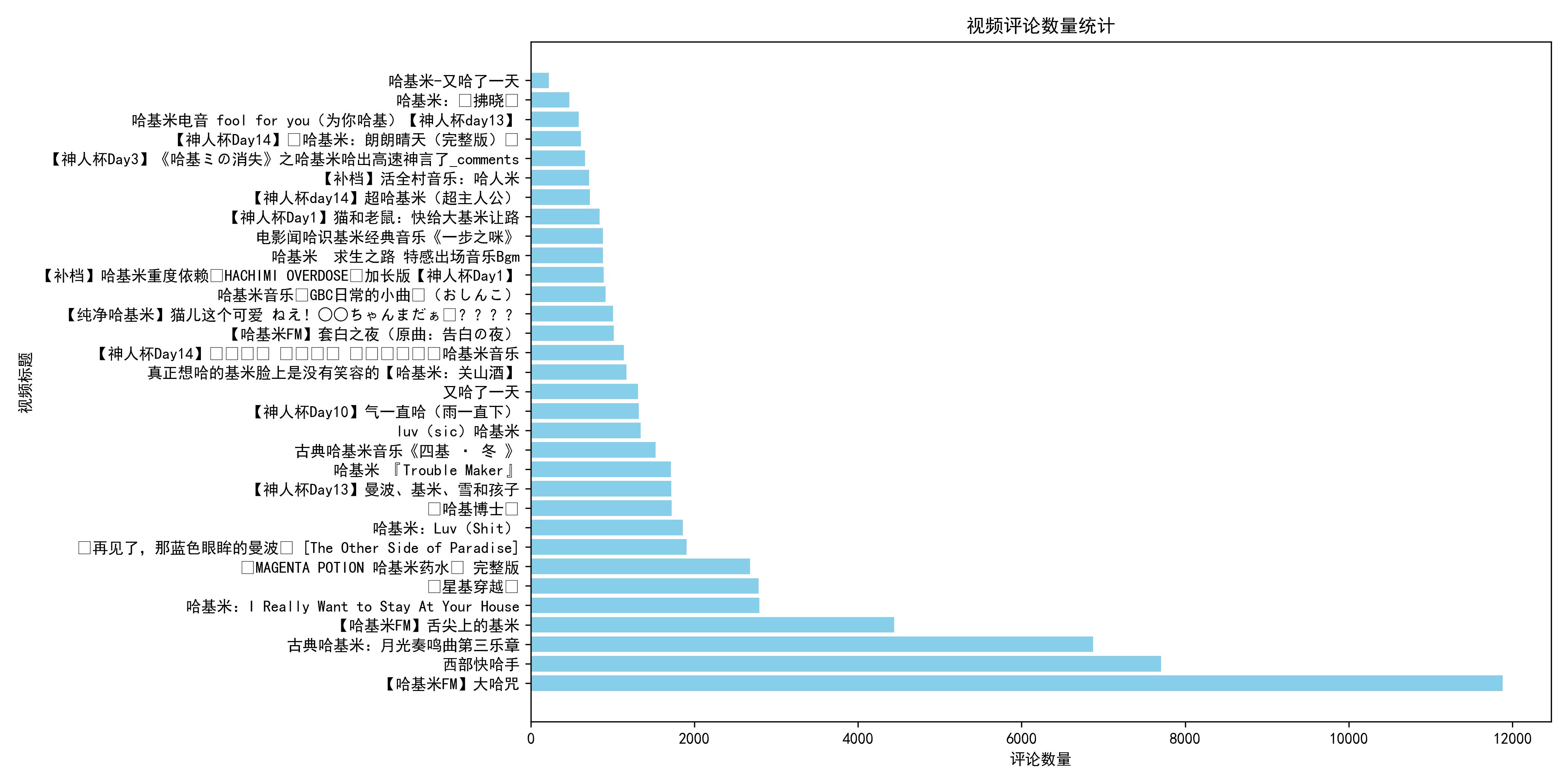
3.1.2 文本预处理模块
对原始评论数据进行中文分词、停用词过滤、去除表情符号与噪声词处理。针对哈基米音乐评论中出现的网络用语、表情词和拟声词,特别扩充了自定义词典与停用词库,以适配哈基米音乐的社区语言特征。
3.2 实验分析
3.2.1 特征工程模块
采用 TF-IDF 方法提取每条评论的关键词权重,构建评论文本的向量表示;同时提取每位用户的平均情感得分、评论活跃度(评论数与点赞数)、关键词分布等特征,最终形成用户级别的特征矩阵。
3.2.2 用户聚类分析模块
基于用户特征矩阵,分别使用 K-means 与 DBSCAN 算法进行聚类,划分出多个具有相似行为模式的用户群体。利用轮廓系数对不同聚类方案进行评价,并选择最佳聚类结果用于后续分析。
3.3 结果分析
3.3.1 结果可视化模块
通过 PCA 对高维特征降维后,结合散点图直观呈现用户聚类结果。进一步绘制用户活跃度分布、情感倾向分布及词云图,全面展示各用户群体的兴趣关键词与行为特征。
3.3.2 分类与标签验证模块
将聚类结果作为标签,利用随机森林与支持向量机训练分类模型,验证用户特征与标签的一致性。通过准确率、召回率与 F1 值综合评估分类效果,确保用户划分的合理性与模型的泛化能力。
4 用户画像分析与结果可视化
4.1 构建用户画像
4.1.1 聚类结果分析
用户群体概述
本研究根据评论频次、点赞量与情感得分,将45304名B站用户划分为五大群体:高活跃高情感用户(簇 2)评论数与点赞数均远超平均,常用“上头”“爆笑”“再来一遍”等高互动词;中活跃积极用户(簇 0)评论适中、情感偏正,典型词汇有“治愈”“节奏感”“超喜欢”;潜水型用户(簇 3)评论量极低但偏好点赞,关键词稀疏;消极情绪用户(簇 4)情感得分偏低,多用“无聊”“不懂笑点”“没意思”等负面词;噪声与离群用户(簇 1)主要为无关内容或表情刷屏,分布于DBSCAN识别的噪声区域。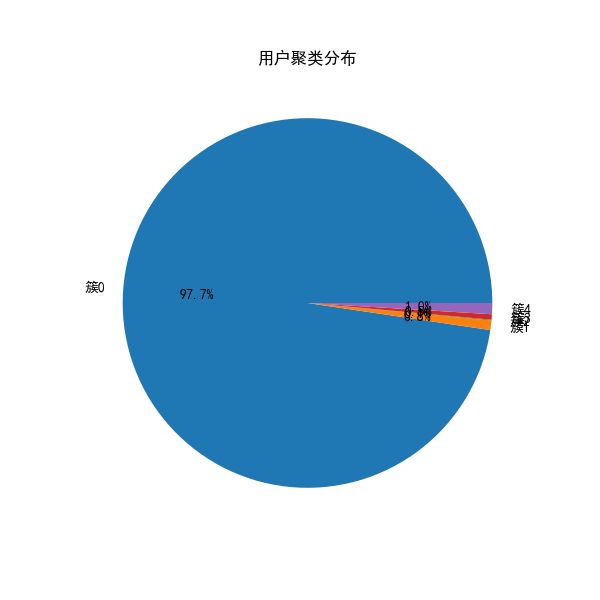

4.1.2 情感倾向与活跃度分布
通过情感得分与活跃度双变量分析发现,用户整体情感倾向偏正,大部分的评论属于正面或积极互动。高活跃用户群体在情感得分上的波动更大,表现出更强的情绪表达倾向。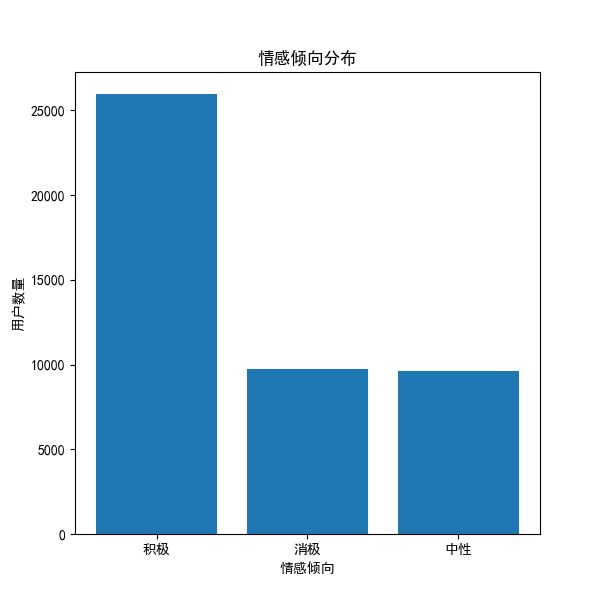
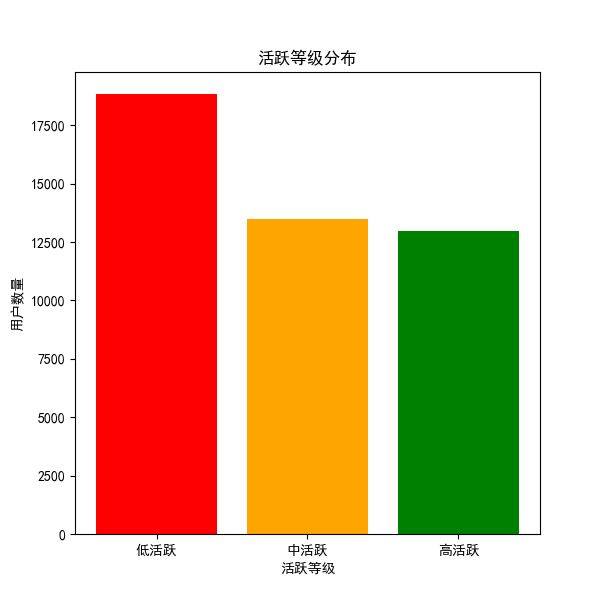
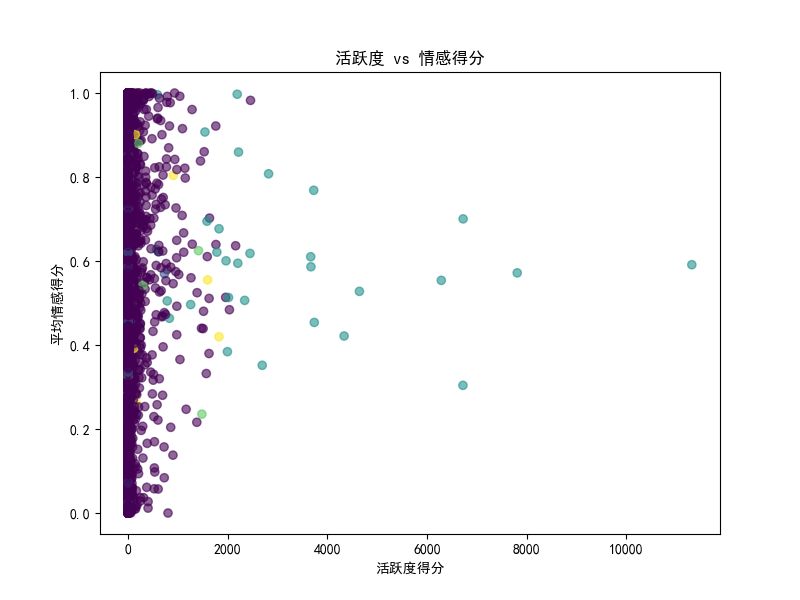
4.2 关键词与兴趣偏好分析
从词云图入手分析,词云显示观众情绪丰富,表情、大哭、流汗等词反映情绪起伏,喜欢、可爱体现认可;video、微笑关注视觉细节;doge、哈哈哈等网络梗增加幽默感;基米、星星等高频词指向特定话题。整体氛围轻松活跃,情感与讨论并存。
4.3 用户标签分类效果验证
Breiman, L.在《Random Forests》中提出随机森林是由多棵决策树组成的集成模型,每棵树依赖于一个独立、同分布的随机向量。当森林中树的数量趋于无穷大时,其泛化误差几乎必然收敛。随机森林的泛化误差取决于单棵树的强度以及树之间的相关性。通过在每个节点采用随机特征划分,可以获得与 Adaboost 相当甚至更优的错误率,同时对噪声更具鲁棒性。随机森林内部估计可用于监控错误率、树的强度与相关性,并用于分析增加划分特征数的影响。此外,随机森林内部估计还可用于衡量变量的重要性。该方法同样适用于回归问题。^[Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324] 而Cortes, C., Vapnik, V.在《Support-vector networks》论证了支持向量网络是一种新型的两类分类学习机器。该方法将输入向量非线性映射到高维特征空间,并在该空间中构造线性决策面。所设计的决策面具有良好的泛化能力。早期的支持向量机应用仅限于可完全分离的训练数据集,本文将其推广至不可分离的情形。实验表明,采用多项式输入变换的支持向量网络具有优异的泛化性能,并通过与其他经典机器学习算法在光学字符识别任务上的对比验证了其优势。^[Cortes, C., Vapnik, V. Support-vector networks. Mach Learn 20, 273–297 (1995). https://doi.org/10.1007/BF00994018] - 随机森林更侧重于模型集成,通过降低方差提升性能,适用于高维、缺失数据或噪声较多的应用场景。 支持向量机更侧重于构造间隔最大的决策边界,适用于复杂的非线性分类任务,尤其在小样本、高维数据中表现突出。因此这两个算法都很适合作为用户标签分类效果验证。
随机森林分类整体准确率高达96%,对多数类(0类)具有极佳的精度与召回率(precision=0.98, recall=0.99),SVM准确率更高(98%),但严重偏向多数类,F1 值均在 0.9 以上,表明聚类标签具有较高的可区分性与分类稳定性。这一结果验证了基于评论特征构建用户画像的有效性,同时为平台后续实时用户画像系统的设计提供了理论基础。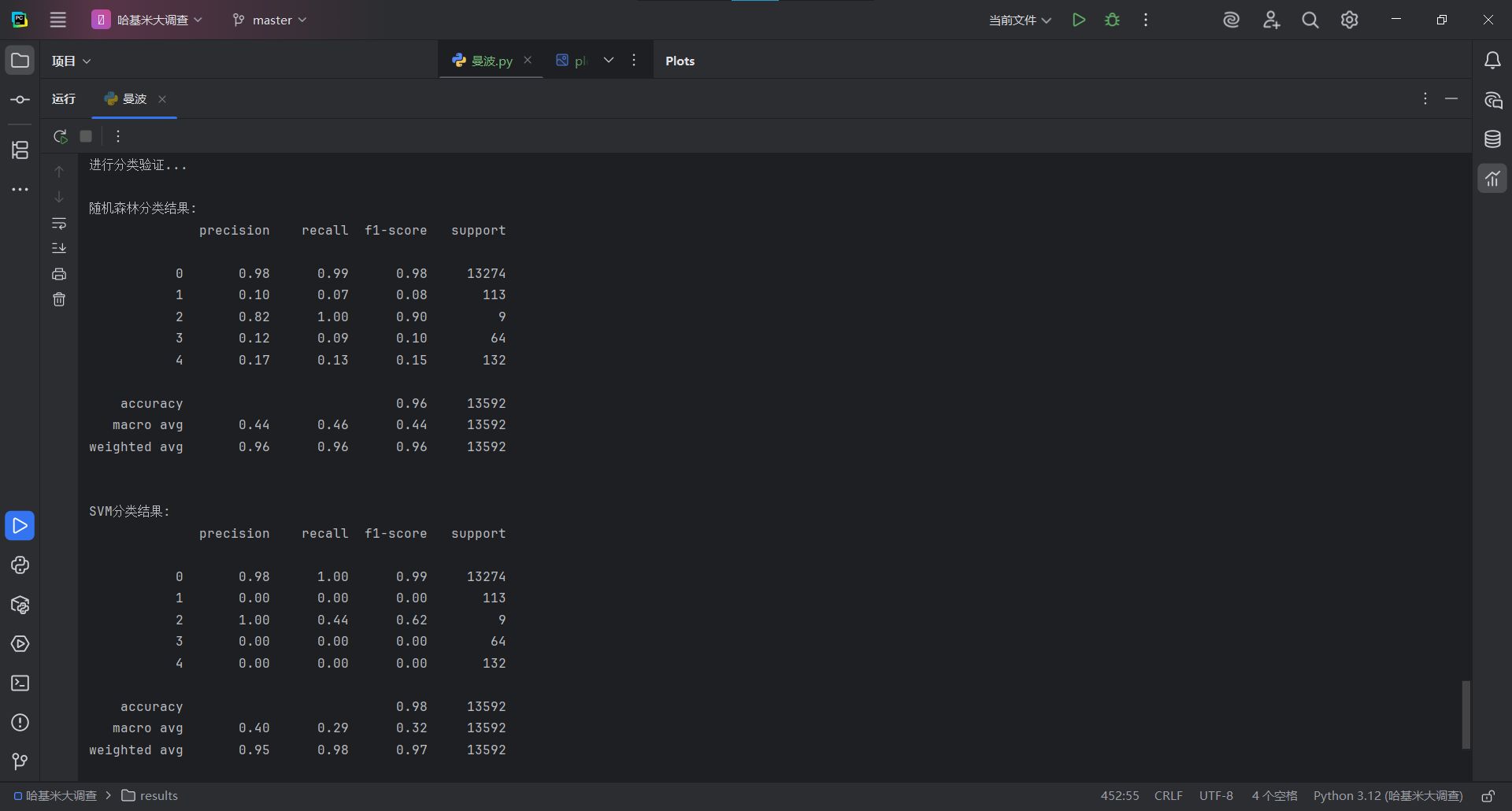
5 总结与展望
本研究针对 Bilibili 哈基米音乐视频的评论数据,基于用户文本行为特征与情感倾向,构建了一套用户画像分析与分类体系。通过中文文本预处理、TF-IDF 特征提取、情感分析、聚类算法与分类模型等方法,深入挖掘了用户的行为模式与兴趣偏好。
研究结果表明,哈基米音乐视频的评论用户可以明显划分为高活跃高情感、中活跃积极、潜水型、消极情绪与噪声用户五大类群体。不同用户群体在评论关键词、活跃度、情感倾向上呈现显著差异,尤其高活跃用户在社区氛围塑造与话题引导中具有重要影响力。这一发现为 Bilibili 平台的个性化推荐优化、社区管理与舆情监测提供了有价值的数据支持。
此外,通过分类模型验证,本研究进一步确认了用户划分类别的合理性与特征稳定性,说明基于评论数据构建的用户画像在实际应用中具备较强的预测与迁移能力。
未来工作将从以下四方面拓展:引入投币、分享、收藏等行为数据,完善用户画像;应用BERT模型提升情感分析精度;构建画像系统,实现兴趣追踪与个性推荐;推广至其他垂直视频领域,验证方法通用性与跨域适应性。
综上所述,本研究不仅丰富了短视频社区用户画像分析的研究视角,同时为哈基米音乐文化现象的传播与社区运营策略提供了科学依据。后续可持续关注哈基米音乐的发展趋势与用户生态变化,进一步优化算法模型与用户分群策略。